Supertonic v3: A Deeper Dive into the Next-Generation On-Device TTS Engine
Supertone has unveiled Supertonic 3, the latest iteration of their on-device, ONNX-based text-to-speech system. This update brings a host of enhancements including support for 31 languages, significantly fewer reading errors, and the addition of expression tags. In this Q&A, we unpack the major changes and capabilities of Supertonic v3, exploring how it compares to its predecessor and what it means for developers building voice interfaces.
What is Supertonic v3 and why is it significant?
Supertonic v3 is the third generation of Supertone's on-device text-to-speech model, built on the ONNX runtime for efficient inference directly on devices like smartphones, IoT gadgets, and edge servers. Its significance lies in its ability to deliver high-quality, multilingual speech synthesis without relying on cloud servers, ensuring low latency, privacy, and offline capability. Compared to open TTS systems that often require 0.7B to 2B parameters, Supertonic v3 uses only about 99 million parameters, making it much smaller and faster while still expanding its language reach from 5 to 31 tongues. It also introduces expressive tags (like <laugh> and <breath>) for injecting prosody directly into text, and dramatically reduces repeat and skip failures that plagued earlier versions. For developers, this means a lightweight, privacy-preserving TTS engine that can run on a CPU with minimal memory usage and startup time.
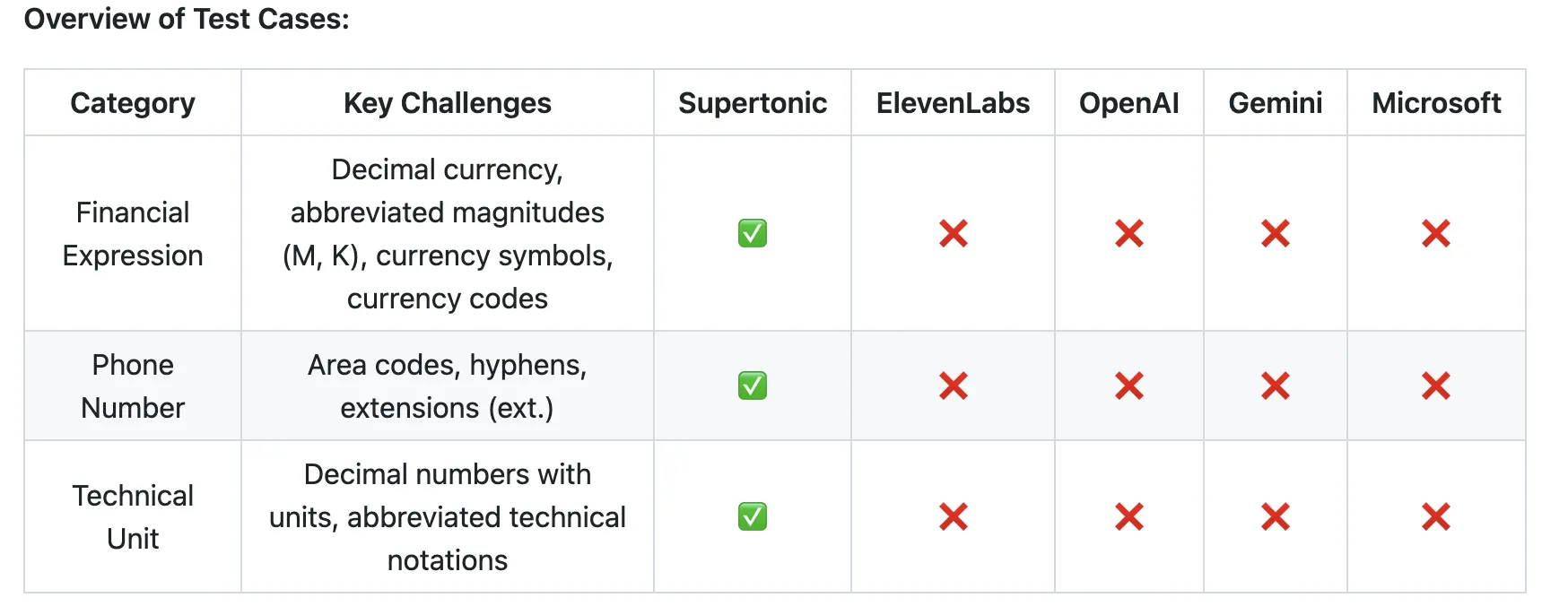
How many languages does Supertonic v3 support, and which ones are new?
Supertonic v3 now covers 31 languages via ISO language codes, up from just 5 in v2. The original release supported English, Korean, Spanish, Portuguese, and French. The new additions include: Japanese, Arabic, Bulgarian, Czech, Danish, German, Greek, Estonian, Finnish, Croatian, Hungarian, Indonesian, Italian, Lithuanian, Latvian, Dutch, Polish, Romanian, Russian, Slovak, Slovenian, Swedish, Turkish, Ukrainian, and Vietnamese. This broad coverage makes it suitable for global applications without the need for multiple specialized models. A special ‘na’ (not applicable) fallback handles text where the language is unknown or outside the supported set, ensuring the system doesn’t break when encountering unsupported languages. The language expansion came with only a modest increase in model size—the public ONNX assets total 404 MB on disk—keeping the system ideal for on-device deployment where storage and bandwidth are limited.
What improvements in reading accuracy does v3 offer?
One of the key pain points in v2 was the occurrence of repeat and skip failures—where the TTS would loop on a word or jump ahead in the text, resulting in unnatural or unintelligible speech. Supertonic v3 specifically targets these errors, reducing them substantially through refinements in the duration predictor and the text-to-speech alignment mechanism. The model now integrates Length-Aware Rotary Position Embedding (LARoPE), which improves how the system aligns text tokens with their corresponding acoustic features, thereby preventing misreadings. Additionally, Self-Purifying Flow Matching training makes the model more robust to noisy data labels, further cutting down on phonetic mistakes. While exact numbers aren’t provided, developers report noticeably fewer glitches and more consistent pronunciation across the 31 languages, especially in the shared language set where speaker similarity also improved.
What are expression tags and how do they work?
Expression tags are a new feature in Supertonic v3 that let developers embed prosodic cues directly into the input text. Supported tags include <laugh>, <breath>, and <sigh>. Instead of needing a separate preprocessing pipeline or a dedicated expressiveness model, you simply insert the tag where you want the effect to occur. For example, inputting “That’s hilarious <laugh> I can’t believe it” will cause the speech engine to insert a natural-sounding laugh at that point. This is particularly useful for voice assistants, audiobooks, and accessibility tools where emotional nuance matters. The tags are lightweight and processed inline, so they don’t increase latency or require extra compute. Supertone hints at expanding the tag set in future releases, but these three cover the most common prosodic modifications.

How does the architecture of v3 differ from v2?
The fundamental architecture of Supertonic v3 retains the same three-component design as v2: a speech autoencoder that compresses audio into latent representations, a flow-matching text-to-latent module that converts text to those latent features, and a duration predictor for natural timing. However, v3 incorporates two key enhancements: Length-Aware Rotary Position Embedding (LARoPE) and Self-Purifying Flow Matching. LARoPE improves alignment between text and acoustic features, reducing misreadings. Self-Purifying Flow Matching trains the model to filter out noisy labels during training, making it more reliable in real-world conditions. These architectural changes, while not radically different, lead to measurable gains in accuracy and expressiveness. The model size grew only slightly (to ~99M parameters) to accommodate the expanded language set and new features, keeping it far smaller than cloud-based alternatives.
How does Supertonic v3 compare in speed and efficiency to alternatives?
Supertonic v3 is designed for on-device inference and runs exceptionally fast even on CPUs. According to Supertone, the model can generate speech in as few as 2 inference steps thanks to flow matching, which samples faster than diffusion models at low step counts. In benchmarks, it outperforms larger systems (0.7B–2B parameters) running on A100 GPUs in terms of latency when deployed on a typical laptop CPU. Memory consumption is also kept low—the public ONNX assets total 404 MB on disk, and runtime memory footprint is minimal compared to cloud TTS models. For developers, this means instant startup times and the ability to run TTS on battery-powered devices. The trade-off is that v3 may not match the absolute highest fidelity of very large neural TTS, but for most applications, the sound quality is more than adequate and the efficiency gains are dramatic.
What is the Voice Builder and how does it relate to v3?
Alongside Supertonic v3, Supertone launched the Voice Builder, a tool that allows developers to create custom, edge-native TTS models from their own voice recordings. This is a separate product but complements v3 by enabling personalized voices that can be deployed on device. The Voice Builder uses the same underlying ONNX runtime and flow-matching architecture, so custom models benefit from the same efficiency and language capabilities. For businesses that need a specific voice—such as a brand spokesperson or a character in a game—Voice Builder eliminates the need to train large models from scratch. Developers record a few hours of speech, and the tool generates a compact TTS model that runs locally. While not part of v3’s core release, it’s a significant ecosystem addition that leverages the same technology stack.